Data engineering is undoubtedly one of the fastest-growing fields of technology and many companies are expanding the responsibility of their data teams to better manage the data stack. Gone are the days when it was simply batch-ingested ETL to analytics dashboards. Companies are increasingly seeking to move to sophisticated data workflows and pipelines that ensure data is at the heart of strategic value for the company. Thus, data analytics, machine learning, and other emerging technology are learning to increase complexity in the workflow. Here are 10 data engineer topics every data team should concern themselves with.
- #1. Cloud Engineering
- #2. Data Engineering Programming
- #3. Big Data Management
- #4. Scripting SQL, NoSQL, and GraphQL
- #5. Data Integration, and Data Orchestration
- #6. Data Quality
- #7. Data Discovery Data Cataloging, and Data Governance
- #8. Data Privacy, Security
- #9. Data Analytics and Data Visualization
- #10. Data Architecture and Data Fabric
- How to learn more about data engineering
#1. Cloud Engineering
While maintaining some on-premise capabilities, many companies have switched much of their data workflows to the cloud. Data teams are moving beyond SaaS to IaaS (Infrastructure as Service) and/or PaaS (platform as a service) for application development. Thanks to cloud providers’ increasing convenience, performance reliability, and improved security, this will continue to be a strong trend. Outsourcing much of the engineering complexity to cloud providers has clear benefits. However, this convenience still leaves data engineers with many challenges such as when to scale up or down, integrating multiple systems across different cloud providers, and dealing with ever-increasing security threats. Arguably the biggest concern at the moment is minimizing cloud service costs while building out and managing increasingly complex cloud infrastructure.
#2. Data Engineering Programming
Despite the proliferation of data infrastructure platforms and tools, custom coding is still required to bind data workflows and pipelines together and complete the journey from data ingestion to end-use delivery. Code-as-workflows is where much of the work is done and
programming languages that are top of mind for data teams include Python, Java, and Scala with Julia also getting traction, especially in AI and ML. Interestingly, Jupyter Notebook, which is popular with data scientists, seems to be a favorite of some data teams despite notebooks’ temporal nature. Of note, many vendors promise low-code or no-code solutions and these services are part of the automation trend, but overall, programming is a strong requirement for data teams.
#3. Big Data Management
Relational databases, NoSQL datastores, data warehouses, and data lakes are all important elements of the modern data stack that allow for large data flows and integration of data from multiple data scores and can handle normalized and non-normalized data. They provide the foundation that other parts of the data stack rely on, including data quality, data governance, data dictionaries, and catalogs. The ultimate goal for many organizations is to break down data silos and democratize data through self-service platforms. Overall, data teams are being tasked with providing a “single-pane-of-glass” that allows downstream users to access all of their big data in one place without needing to switch between different data stores’ dashboards to view different types of data, and provides a holistic view of their data.
#4. Scripting SQL, NoSQL, and GraphQL
While analogous to programming, SQL and its derivatives provide easier, faster, and more flexibility to query and manipulate data. Despite the promises of no-code or low-code solutions, SQL and its derivations are intuitive to use, easy to learn, and still offer the best of flexibility coupled with accessibility and simplicity. SQL is retaining its popularity due to many NoSQL vendors having adopted SQ or variations of it. While quite different from SQL, GraphQL is getting a lot of traction thanks to its ability to not rely on structured data, retrieve data from multiple sources with a single request, and work in conjunction with a number of programming languages. SQL and its derivatives are often listed as one of the top 3 requirements for data engineers.
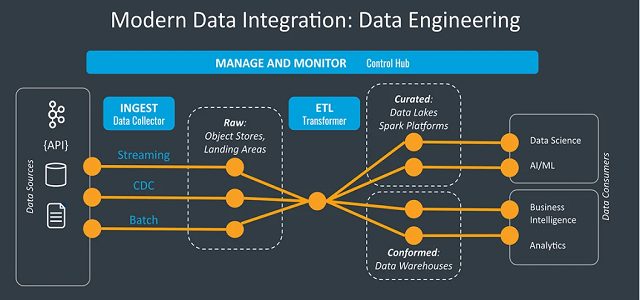
#5. Data Integration, and Data Orchestration
Given the maturity of many data storage solutions, data teams have to contend with a plethora of data sources that span not just the big data systems mentioned, above but also multiple APIs, flat files, data frames, and more. All of these need to be integrated into a single stack. Unsurprisingly, there is no shortage of data integration tools to choose from including open-source projects such as Apache Spark, Nifi, Camel, and Kafka, or platforms like Airbyte or Talend. Most specialize in extracting data from multiple data sources, transforming the data, and then serving to another data store, modeling, or analytics dashboard endpoint. Integrating this data involves coordination, transforming, and monitoring data that often rely on the same platforms including Spark and Nifi. Arguably Apache Airflow is the most popular but other systems such as Streamset have increased adoption, as do platforms that specialize in machine learning workflows such as Apache Flyte which builds on Airflow.
#6. Data Quality
Increasingly sophisticated workflows require much higher standards for data quality to assure stable and high-performing data systems. Long a perennial problem for data teams, data quality issues are often identified only when they’ve traveled far down the pipeline, resulting in brittle workflows that lead to data downtime. New tools and techniques are emerging such as elevating data to a first-class citizen to finally get to the root of the problem. One example is data type checking in the data system so that data errors are caught sooner. Combined with data validation, new techniques such as data versioning, data lineage, and data governance help ensure data quality. Teams are expected to adopt a data quality strategy that is data-centric and ensures data uptime. Many open-source tools and vendor platforms are adapting data quality as part of their service such as Talend, and there is a growing number of standalone tools such as DataCleaner.
#7. Data Discovery Data Cataloging, and Data Governance
Data cataloging and discovery are essential for creating a central reference point for an organization’s data. Cataloging and discovery allow for easy access to data via search, discovery, and visualization. It also allows for more thorough data security by tracking usage and access and compliance with governance policies. However, all of this requires data standardization across multiple sources and workflows to ensure compliance. Data lineage and quality issues can also negatively impact data discovery and cataloging. Data governance scope expands beyond the data team, and cataloging and discovery allow stakeholders with other roles and responsibilities easy access to data. To help with this, data teams are leveraging open-source platforms such as include Apache Atlas for discovery, cataloging, and governance, as well as Apache Amundsen.
#8. Data Privacy, Security
Data governance sets the standards for a company’s data policy, and most importantly, its privacy and security. The ever-evolving need for privacy and security requires that they are architected into every step in the workflow. This is compounded by the fact that many data tools need to be built from the ground up with security and privacy in mind, whether it’s the storage solutions or data endpoints. Many companies look to encode GDPR, HIPAA, or CCPA compliance. Cloud providers handle some of the burden by adding privacy features to their offerings, but data teams with local and domain context in mind need to layer on extra security and privacy all along the workflow. Data teams are also looking to new emerging techniques like differential privacy which allows the analysis of sensitive data while protecting the privacy of the original data source.
#9. Data Analytics and Data Visualization
Many of the current leading analytic platform providers predate data engineering including Tableau, Power BI, and SAS. They have maintained their leading position by quickly adapting new data sources, migrating to the cloud, and enhancing their various services. However, tools, popular with data science and machine learning engineers, are adding to the analytics and visualization ecosystem. Jupyter Notebook is now becoming a popular choice for shareable analytics as are cloud-first solutions like Google Colab. Add to that the popularity of open-source analytics dashboards and visualization projects such as Apache Preset and Apache Superset. Additionally, platforms that provide data management, cataloging, and discovery as previously mentioned such as Apache Amundsen and Marquez provide feature-rich data analysis tools and metadata projects.
#10. Data Architecture and Data Fabric
First coined in 2016, the term “data fabric” is getting renewed interest from data teams. This is unsurprising as many companies are now a decade into strategic data investment that continues to evolve from some organizational value that remains elusive. The goal of data fabric is to help companies more effectively extract value from their data assets to better support a range of strategic data-driven initiatives, such as real-time analytics and machine learning. In reality, this means the effective implementation of many, if not all of the topics mentioned above, including enhanced data integration, improved access, data governance, and security all the while being scalable and flexible.

How to learn more about data engineering
As you can see above, there are numerous components that go into the stack and use of data engineering tools and workflows. This makes learning all about data engineering difficult to do with just books or videos. This January 18th, we’re hosting the first-ever Data Engineering Live Summita free virtual conference designed to help you make data actionable across the board.
This exciting new conference will cover pivotal topics related to data engineering, including, but not limited to:
Cloud Engineering | Database Infrastructure | Data Orchestration | Data Privacy and Security | Big Data Frameworks | Data Analytics | Data Workflows & Pipelines | Programming for Data Engineering | DataOps | Data Catalogs & Data Discovery | Data Quality | Data Visualization Dashboards | and more to come.
Start off your new year right and make 2023 the year you make a difference with your data. Register here for the free Data Engineering Live Summit!





