
Case Study: evaluate a Complex RAG application
In the RAG pipeline below, a query is first sent to a classifier to decide the intent of the question and then passed through three separate retrievers. The Base Retriever runs a vector search in the vector database, the BM25 Retriever uses keyword search through documents, and a HyDE generator creates hypothetical context documents and then retrieve semantically similar chunks. A reranker which uses Cohere LLM reorder and compresses the retrieved chunks based on relevance and finally feeds into the LLM to produce an output.
To build an evaluation Pipeline tailored to this complex RAG application, you can define the Modules as follows using continuous-eval.
from continuous_eval.eval import Module, Pipeline, Dataset, ModuleOutput
dataset = Dataset("data/eval_golden_dataset")
classifier = Module(
name="query_classifier",
input=dataset.question,
output=str,
)
base_retriever = Module(
name="base_retriever",
input=dataset.question,
output=Documents,
)
bm25_retriever = Module(
name="bm25_retriever",
input=dataset.question,
output=Documents,
)
hyde_generator = Module(
name="HyDE_generator",
input=dataset.question,
output=str,
)
hyde_retriever = Module(
name="HyDE_retriever",
input=hyde_generator,
output=Documents,
)
reranker = Module(
name="cohere_reranker",
input=(base_retriever, hyde_retriever, bm25_retriever),
output=Documents,
)
llm = Module(
name="answer_generator",
input=reranker,
output=str,
)
pipeline = Pipeline([classifier, base_retriever, hyde_generator, hyde_retriever, bm25_retriever, reranker, llm], dataset=dataset)
To select the appropriate metrics and tests to a module, you can use the eval and tests fields. Let’s use the answer_generator module as an example and add 3 metrics and 2 tests to the module.
from continuous_eval.metrics.generation.text import (
FleschKincaidReadability,
DebertaAnswerScores,
LLMBasedAnswerCorrectness,
)
from continuous_eval.eval.tests import GreaterOrEqualThan
llm = Module(
name="answer_generator",
input=reranker,
output=str,
eval=[
FleschKincaidReadability().use(answer=ModuleOutput()),
DebertaAnswerScores().use(
answer=ModuleOutput(), ground_truth_answers=dataset.ground_truths
),
LLMBasedFaithfulness().use(
answer=ModuleOutput(),
retrieved_context=ModuleOutput(DocumentsContent, module=reranker),
question=dataset.question,
),
],
tests=[
GreaterOrEqualThan(
test_name="Readability", metric_name="flesch_reading_ease", min_value=20.0
),
GreaterOrEqualThan(
test_name="Deberta Entailment", metric_name="deberta_answer_entailment", min_value=0.8
),
],
)
Once you have the pipeline set up, you can use an eval_manager to log all the intermediate steps.
eval_manager.start_run()
while eval_manager.is_running():
if eval_manager.curr_sample is None:
break
q = eval_manager.curr_sample["question"]
eval_manager.log("reranker", Document)
eval_manager.next_sample()
Finally you can run the evaluation and tests,
eval_manager.run_metrics()to run all the metrics defined in the pipelineeval_manager.run_tests()to run the tests defined in the pipeline
Below is an example run on the pipeline. In this visualized output, you can see that the final answer is generally faithful, relevant, and stylistically consistent. However, it is only correct 70% of the time. In this case you can trace back the performance at each module (it looks like on of the Retrievers is suffering at Recall that’s worth investigating).
Pipeline metrics and tests generated using Relari.ai
Check out more examples:
To check out more complete examples, we have created four examples with complete code. github.com/relari-ai/examples. The applications themselves are built using LlamaIndex and @LangChain and have continuous-eval evaluators built-in.
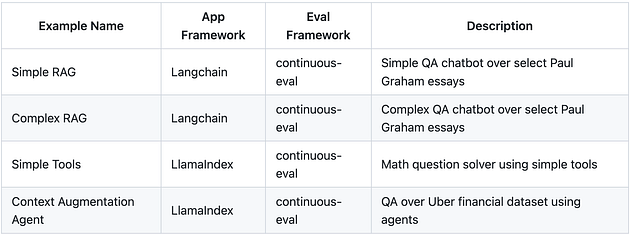
Full examples of multi-step applications with evaluators built-in (github)
Try it in your application:
Here’s the link to the open-source continuous-eval: github.com/relari-ai/continuous-eval
For more info visit at Times Of Tech





